

Is Structured Prompting Dead?
Exploring what happens when testing prompt format


“Structured prompting is dead.”
The proclamation came through my feeds like so many others.
Yet another casualty of AI’s rapid evolution. As models get smarter, the argument goes, we no longer need to carefully design our instructions.
“Just talk naturally. The AI will figure it out.”
Like so many claims like this, its not been tested publicly much (partly because its pretty difficult when you get into the nitty gritty). While some have researched AI outputs (like this Microsoft study), we still lack a clear understanding of why different structures create such different outcomes.
I’ve been using structured prompts exclusively in my work—for teaching, for content generation, and for the AI writing tools I build with students.
How we shape information for AI isn’t just about getting better outputs or faster processing. It’s about choosing your rhetorical stance in a human-machine collaboration.
Yes, its because they’ve always delivered consistent results, but also its much easier for humans to work with well-designed instructions, so why not machines.
It works, so why bother testing. Well, this discussion about the death of prompting got me wondering.
What am I missing by not comparing approaches? Am I clinging to unnecessary complexity while everyone else has moved on to conversational simplicity?
So I ran an experiment.
Not to defend structured prompting, but to understand what structure actually does—to processing time, to cost, to output behavior.
The results tell a story about information design that goes beyond prompt engineering.
How we shape information for AI isn’t just about getting better outputs or faster processing. It’s about choosing your rhetorical stance in a human-machine collaboration.
The format becomes a cue that shapes not just what the AI produces, but how it understands its role in the conversation.
When I say “rhetorical stance,” I mean the relationship and role that gets established between speaker and audience through how something is communicated.
Think of it like this: the same information delivered in a legal contract, a friendly email, and a technical manual creates fundamentally different relationships between writer and reader.
The legal contract positions the writer as an authority establishing binding terms.
The friendly email creates a peer-to-peer collaboration.
The technical manual sets up an instructor-student dynamic.
With AI, prompt format works the same way by signaling to the model what kind of interaction this is.
JSON says “we’re doing technical documentation now.” Natural language says “we’re having a focused discussion.” Unstructured rambling says “let’s explore ideas together.”
The format becomes a cue that shapes not just what the AI produces, but how it understands its role in the conversation.
How I Performed the Test
I took a prompt I’d developed for the WAC Clearinghouse prompt library (revised version coming soon)—a complex instruction set for helping student writers analyze their microessays through rhetorical appeals.
This wasn’t a simple “write me a paragraph” task. It required the AI to perform multi-layered analysis: identify patterns across texts, develop ethos strategies, create emotional connections, and suggest logical organization. The kind of sophisticated content work that professionals do every day.
Using PromptLayer’s testing tools, I ran four variations in a single session to ensure clean comparisons:
1️⃣ The structured prompt with semantic tags. My original version with clear sections like [ROLE], [CONTEXT], [TASK], and specific subsections for different types of analysis.
2️⃣ The structured prompt with tags removed. All the organization remained—the logical flow, the clear sections—but without the explicit XML-style markers.
3️⃣ An unstructured version. I asked Claude to rewrite the same prompt as if a student were explaining the task conversationally. Same requirements, same goals, but delivered as natural language.
4️⃣ A JSON version. After a LinkedIn commenter asked if I meant JSON when I said “structured,” I converted the entire prompt to JSON format—pure data syntax with nested objects and arrays.
Each test tracked three metrics: processing time, cost, and output token count. I also compared outputs to see if there were any rhetorical comparisons to be made.
While I think the results were enlightening, I should be clear that this is an imperfect test. Other factors like how busy a server or API is can influence these statistics. But I think it is good enough to make some observations.
What the Numbers Revealed
The patterns were striking, though not for the reasons I initially thought.
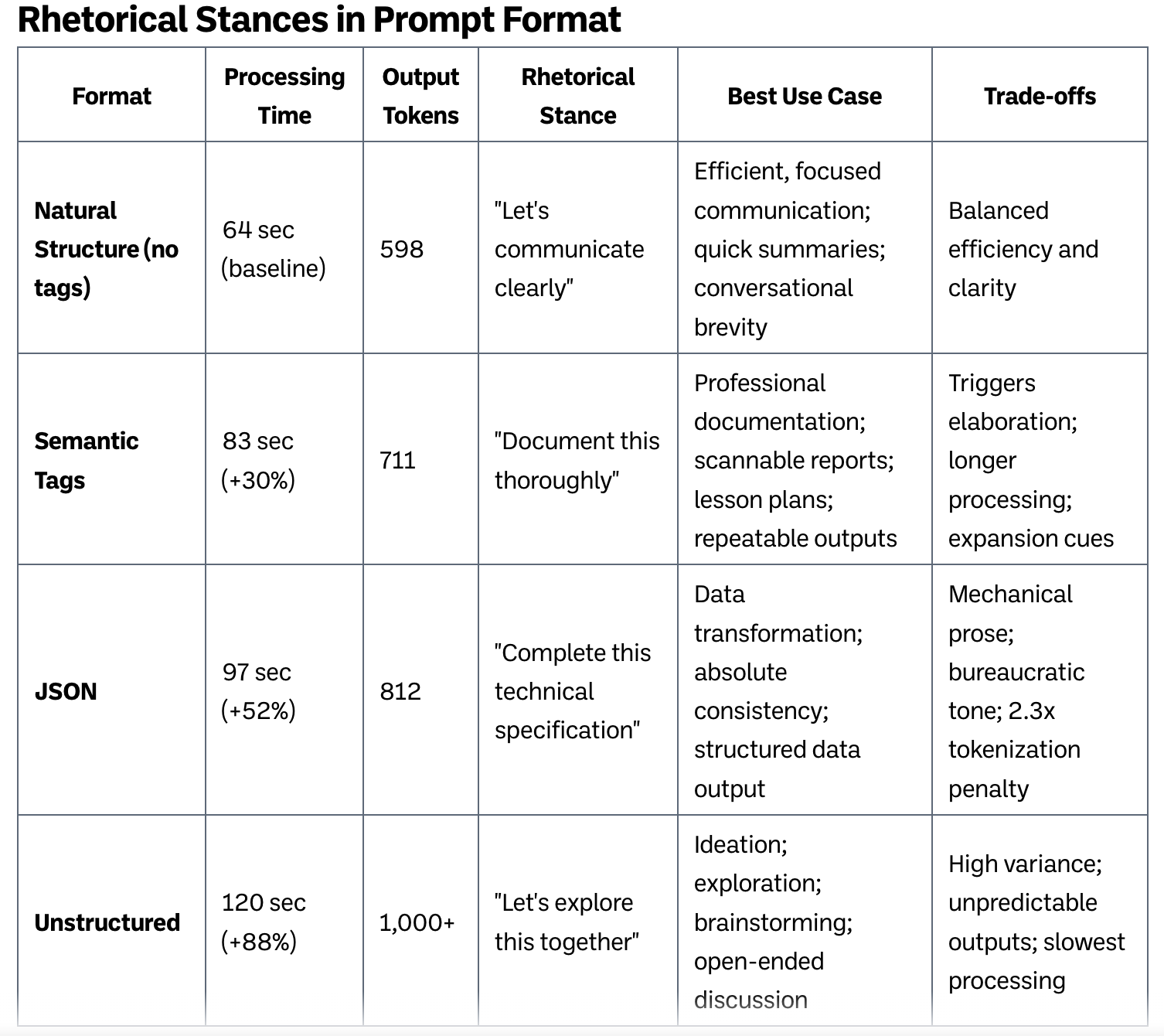
The structured prompt without semantic tags completed in 64 seconds producing 598 output tokens. This provided a baseline that was pretty clean and efficient.
Adding semantic tags increased time to 83 seconds with 711 output tokens. My theory is that the tags acted as “expansion cues,” signaling that each section deserved elaboration.
The JSON format took 97 seconds and generated 812 tokens. But further research shows that it wasn’t struggling to process JSON.
The format triggered what researchers call “technical documentation mode” that pattern matches more technical genres, producing exhaustive and mechanical prose.
The unstructured version was slowest at 120 seconds with over 1,000 output tokens—nearly double the baseline. My theory is that the conversational prompt triggered exploratory generation, treating the task as an invitation to discuss rather than execute.
Initially, I assumed the timing differences reflected processing difficulty—surely JSON must be harder for the model to parse. But the math tells a different story. In language models, input processing happens in parallel (~0.24ms per token), while output generation is sequential and 20-400x slower per token.
Those 214 extra tokens JSON produced account for most of the 33-second timing difference. The model wasn’t struggling to read JSON—it was taking longer because JSON triggered a more verbose response mode.
This actually makes the finding more interesting. It’s not about computational efficiency but about rhetorical stance. Different formats don’t just organize information differently. They cue fundamentally different generation patterns:
JSON: Triggers technical documentation mode (exhaustive, formal, mechanical)
Natural structure: Activates focused communication patterns
Semantic tags: Signals “elaborate on each section” behavior
Unstructured: Invites exploratory discussion
The character of the output revealed even more than the metrics. The JSON response read like a compliance document—numbered sections, technical language, etc.
After completing my tests, I discovered that Microsoft researchers had recently published similar findings, documenting performance variations up to 40% based solely on prompt format across multiple GPT models and benchmarks.
Their comprehensive study validates how prompt format significantly affects model performance, with no universal optimal format even within the same model family.
That’s to say … Prompt format is rhetorical!
Their research confirms several key points:
GPT-3.5 models showed dramatic performance swings—in some cases over 200% improvement when switching formats
Different models prefer different formats (GPT-3.5 favoring JSON, GPT-4 favoring Markdown)
Larger models like GPT-4 demonstrate greater resilience to format changes, though notably not immunity
So my findings aren’t necessarily quirks of my specific test prompt or isolated anomalies. The pattern is systemic across tasks and models.
However, what the Microsoft research doesn’t address is why these patterns exist. They document the what but not the why.
The progression from natural structure to mechanical syntax reflects a fundamental principle about human-AI communication.
Why Structure Behaves Like Rhetoric
Structure doesn’t just organize information; it establishes the collaborative stance between human and AI.
Optimal performance comes from matching structure to the rhetorical nature of the task. Natural structured writing processes fastest because it aligns with how the model was trained to understand human communication.
When we provide semantic tags, we’re creating what I call “expansion cues.” The model sees [ETHOS STRATEGY] and understands this as a space requiring elaboration. It sees [TASK] and knows to provide comprehensive detail. Tags act like rhetorical zones that encourage certain types of discourse.
JSON creates an entirely different rhetorical space that focues on compliance and formality. This activates what researchers identify as “technical mode,” producing exhaustive, formal outputs. The 2.3x tokenization penalty of JSON (all those brackets, quotes, and repeated keys) compounds the effect, consuming attention budget without adding semantic value.
Each format implies a different relationship between human and machine.
Natural language says: “Let’s communicate clearly”
JSON says: “Complete this technical specification”
Semantic tags say: “Document this thoroughly”
Unstructured says: “Let’s explore this together”
The irony? The “most machine-readable” format (JSON) produces the least useful output for human consumption, while natural human organization produces the most efficient machine behavior.
This connects directly to my research on chunk size in RAG systems. Just as different chunk sizes serve different types of questions (64 tokens for facts, 1024 for complex reasoning), different prompt structures serve different collaborative needs.
The design isn’t just technical—it’s rhetorical. We’re not optimizing for machines. We’re designing collaborative spaces.
The Scale Mathematics
For a single prompt, these differences might seem academic. An extra 56 seconds here, three-tenths of a cent there. But content operations don’t run on single prompts. They run on thousands, tens of thousands, millions of interactions.
So let’s make this concrete. Say you’re running a content operation that processes 1,000 prompts daily—not unusual for automated content generation, customer service, or educational applications.
Switching from unstructured to naturally structured prompts saves 56 seconds per query. That’s 15.5 hours of processing time per day—nearly two full workdays. Over a month, you’re looking at 465 hours of saved processing time.
The cost compounds too. While individual prompt costs seem negligible, at scale the differences matter. Those additional 400+ tokens per response in unstructured prompts mean 40% more data volume. Your storage costs increase. Your analysis tools work harder. Your editors spend more time trimming verbosity.
But the real cost isn’t measurable in dollars or seconds. It’s in variance and character. Unstructured prompts produce unpredictable outputs—sometimes brilliant, sometimes meandering, always different. JSON produces consistent but mechanical prose—reliable but soulless.
When you’re building content operations, you need to choose not just your efficiency point but your rhetorical stance. Do you want exploratory collaboration, professional documentation, efficient communication, or bureaucratic compliance?
A Framework for Prompt Design Decisions
After running these tests and analyzing the patterns, I’ve developed a decision framework that treats prompt structure as a rhetorical choice rather than a technical optimization.
Start with output shape, not input format. Before writing any prompt, define exactly what you need: A three-paragraph summary? A five-point action plan? A detailed analysis with specific sections? Your output requirements should drive your structural choices, not the other way around.
Next, identify your rhetorical needs. What kind of collaboration do you want with the AI?
Natural structure (no tags): For efficient, focused communication. When you need speed and clarity without elaborate formatting.
Semantic tags: For professional documentation requiring consistent sections. When repeatability and scannable output matter more than speed.
JSON: For data transformation tasks or when you need absolute consistency, accepting the trade-off of mechanical prose and slower processing.
Unstructured: For exploration, ideation, or when you want the AI to think expansively about possibilities.
Then assess your scale needs. Running ten prompts a day? The performance differences might not matter. Running ten thousand? Every second and cent compounds. An 88% performance difference between best and worst approaches becomes operationally critical at scale.
The death of structured prompting has been greatly exaggerated. What’s actually dying is the simplistic binary of “structured versus unstructured.” The reality, as these tests reveal, is a spectrum of rhetorical choices, each creating different collaborative dynamics with AI.
Consider your variance tolerance. If you need consistent, repeatable outputs—think templates, reports, standardized responses—structure is non-negotiable. The tighter your structure, the lower your variance. But remember: JSON’s consistency comes with a rhetorical cost. You get reliability but lose voice.
For semantic tags specifically, I’ve found they work best when you need scannable, sectioned outputs that others will consume—documentation, lesson plans, reports. They’re rhetorical markers that say “this content has formal zones.” But they also encourage elaboration, adding processing time and output length.
Skip tags when you need conversational brevity—emails, status updates, quick summaries. The model treats unmarked structure as a cue for flowing prose rather than sectioned content. You get the benefits of logical organization without the expansion behavior that tags trigger.
Avoid JSON unless you explicitly need data structure output or are willing to accept bureaucratic prose for absolute consistency. The processing overhead and rhetorical stance rarely justify its use for content generation tasks.
Where Prompt Engineering Is Actually Heading
The death of structured prompting has been greatly exaggerated. What’s actually dying is the simplistic binary of “structured versus unstructured.” The reality, as these tests reveal, is a spectrum of rhetorical choices, each creating different collaborative dynamics with AI.
What we’re witnessing isn’t the evolution of prompt engineering as a technical skill. It’s the emergence of a new literacy—one where writers understand not just how to communicate with humans, but how to design information for collaborative intelligence.
Where content professionals design not just for reading, but for processing.
Where rhetoric extends beyond human audiences to include artificial ones.
The future is less about structured vs. unstructured and more about developing rhetorical awareness, or understanding how different information architectures create different collaborative possibilities with AI systems.
Sometimes you need the precision of semantic tags for repeatable documentation.
Sometimes you need the efficiency of natural structure for rapid processing.
Sometimes you need the exploration of conversational prompting for ideation.
And yes, sometimes you might even need JSON’s mechanical consistency for pure data transformation.
Understanding structure as rhetoric—not just formatting—becomes essential as AI systems become more central to content work.
This isn’t the end of structured prompting. It’s the beginning of rhetorical information design.
What’s your experience with prompt structure? Have you noticed different AI behaviors with different formatting approaches? I’d particularly love to see tests comparing other structural formats—Markdown, YAML, or even programming language syntax. Drop your observations in the comments, or better yet, run your own tests and share the data. Together, we can map the full spectrum of rhetorical possibilities in human-AI collaboration.
Very interesting research! I might add that prompt format does not only shape the AI’s output, it also shapes the user’s thinking.
Structured prompting helps the user think about the problem and structure their thoughts (and needs)… to select and include the most relevant data (role, context, format, etc.).
This was fascinating. Thanks for reporting back on that experiment.