

User-Backed Taxonomy Handout
An example of how I'm using taxonomies to organize AI collaboration


This taxonomy emerged from Fall 2025 user research conducted by students in our disaster communication project, and illustrates how I’m using taxonomies to organize and structure AI collaboration. Working with the New Hanover Disaster Coalition, students interviewed UNCW students about food security needs during disasters, conducted usability testing on existing emergency documents, and ran card-sorting exercises to understand how people naturally categorize disaster preparation information.
The taxonomy you see below builds directly on student work but has been adapted and refined using an MCP data modeling tool and AI to demonstrate how research-based categorization translates into structured content organization—which then becomes the foundation for knowledge graphs that AI systems can use reliably.
Interested in exploring this in your own work? Check out my course, Writing with Machines. Now available for paid subscribers.
This taxonomy synthesizes work from Fall 2025, when students in ENG 404 (Advanced Professional Writing) and CSC 302 (Intro to AI) collaborated on the foundation for a disaster relief chatbot. ENG students conducted user research with UNCW students about food security during disasters, created taxonomies based on that research, and prepared source documents. CSC students built initial knowledge graphs using Neo4j tools.
This semester, ENG 326 and CSC 322 continue that work by developing functional chatbots. This taxonomy organizes the project so teams can divide the work systematically.
What is a taxonomy and why does it matter?
A taxonomy is a classification system that organizes information into categories and subcategories. You encounter taxonomies constantly—the folder structure on your computer, the way a grocery store organizes aisles, the categories on a news website.
For AI systems, taxonomies matter because they determine how information gets structured, stored, and retrieved. A chatbot answering questions about disaster preparedness needs to “know” that generator safety relates to power outages, which relates to food spoilage, which relates to health risks. Without an organizing structure, the chatbot has no map for navigating these connections.
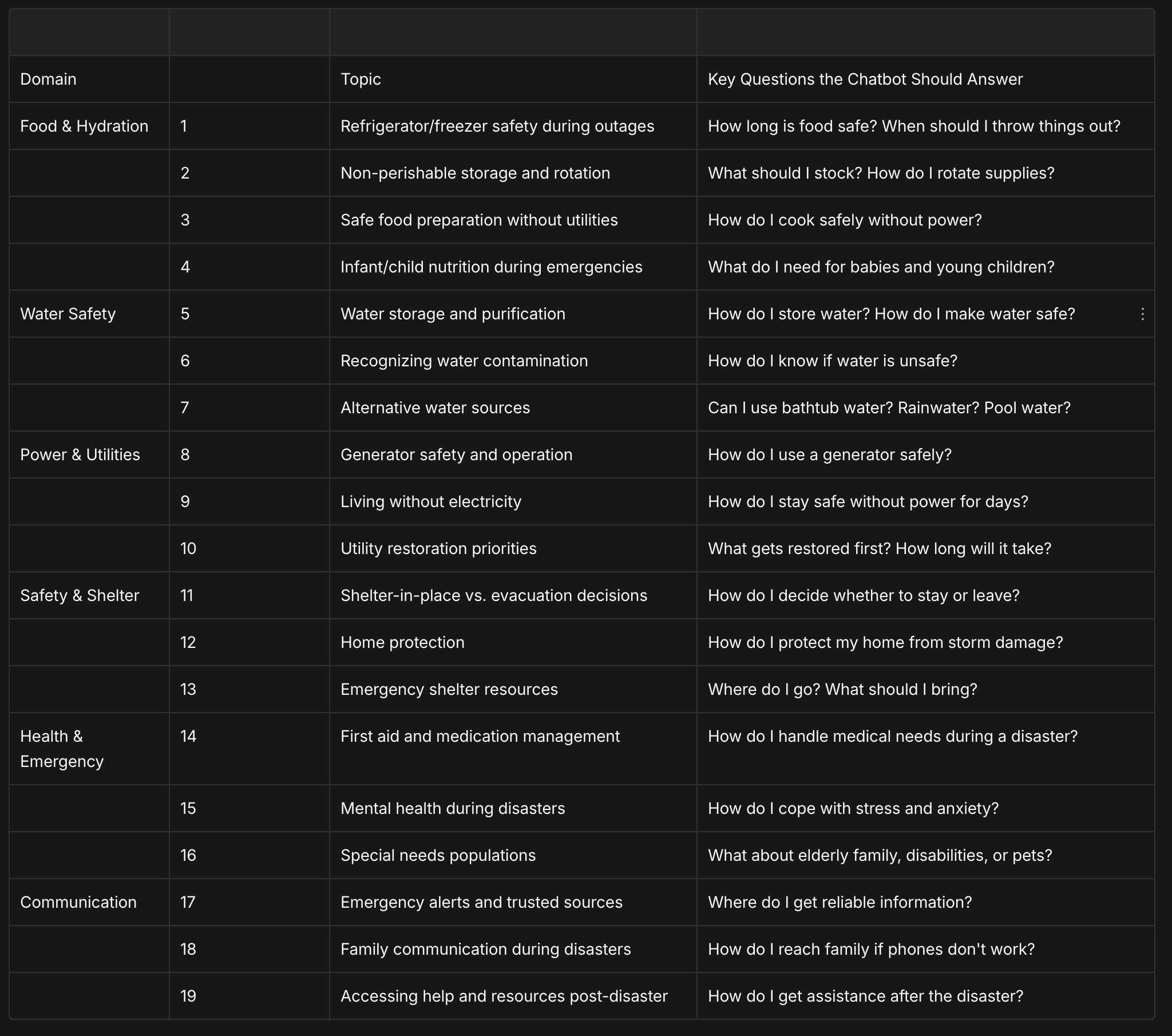
The taxonomy below divides disaster preparedness into domains and specific topics. Each team will own one topic, becoming the experts responsible for gathering authoritative information, structuring it for AI use, and building a chatbot that handles questions in that area.
Taxonomy: Broad Disaster Preparedness Coverage
How teams will use this taxonomy
Each team receives one topic from the taxonomy. Over the semester, teams will:
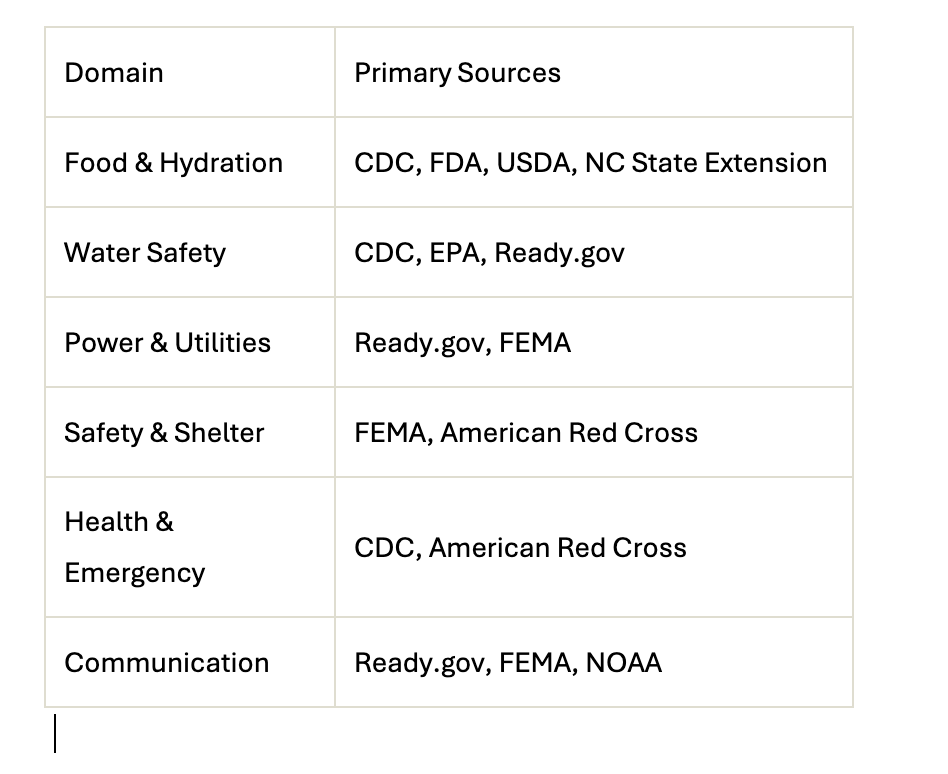
Identify and collect source material. Find authoritative sources (CDC, FEMA, Red Cross, etc.) that address your topic. The Fall 2025 classes prepared some text files already—check there first, then supplement as needed.
Structure the content. ENG students will extract key information and organize it into a consistent format—concepts, tasks, rules, warnings—that works well for AI retrieval. This structured content feeds both your team’s chatbot and a shared repository.
Build and test chatbots. CSC students will build two versions: one without a knowledge graph (baseline) and one with a knowledge graph built from the structured content. Teams will compare performance to see how structured knowledge affects accuracy.
Contribute to the larger project. Your structured content joins a shared repository. Even though each team builds a focused chatbot, the combined work creates a foundation for a more comprehensive system—whether integrated this semester or built upon in future classes.
Authoritative sources by domain
Is your "difference" that you focus on user generated questions, and take it from there? (hierarchical) vs default is focus on topic? (and not map/hierarchical)
What happens with/when sources contradict each other?