

Using Information Types to Build and Evaluate Prompt Structures
Context Lab #13. A more precise approach to prompt evaluation


This post is the reference handout for my ConVex 2026 presentation, “Evidence-Based Prompt Design for AI Writing Systems,” and a follow-up presentation later this week at Information Energy 2026. If you weren’t in either room, everything here is designed to stand on its own.
When an AI system produces a bad answer, most practitioners rewrite the prompt. Sometimes that fixes it. More often, the problem is somewhere else entirely, and without a diagnostic framework, you’re guessing. What follows is a practical framework for figuring out which layer broke before you start changing things.
Most evaluation treats an AI writing system as having two parts: the prompt and the knowledge base. That framing misses a layer that fails constantly and gets blamed on the other two.
There are really three layers, each with its own failure modes.
The prompt layer governs behavior. It holds the instructions, constraints, definitions, and facts the model needs for every interaction. This is content and information too critical to depend on retrieval.
The knowledge base holds content that’s only relevant to specific queries, such as detailed procedures, tool descriptions, location-specific data, anything too voluminous to keep in the prompt without degrading performance.
The retrieval layer connects them. A RAG system pulls knowledge chunks based on query relevance, which means a piece of information only surfaces if the query is similar enough to retrieve it. An MCP server gives AI tools for creating or accessing knowledge.
The practical decision rule: if a missed retrieval would cause a serious failure, the information belongs in the prompt. If it’s only needed for specific queries, it belongs in the knowledge base.
When something goes wrong, the first question isn’t “how do I fix the prompt?” It’s “which layer is this coming from?”
Why information types help
Many practitioners who structure their prompts at all are working from intuitive categories, such as role, context, output format, rules. Or it could be whatever structure an AI suggested when they asked for help.
Those categories aren’t wrong, but they’re ad hoc. They don’t derive from how knowledge actually functions, so they don’t give you consistent criteria for evaluating whether the prompt is doing its job.
Information types provide a more principled heuristic: Task, Concept, Reference, Principle, Process. Each type reflects a genuinely distinct mode of knowing.
Definitions work differently from procedures. Procedures work differently from conditional rules. Conditional rules work differently from facts. Mixing them in the same block makes the prompt harder to evaluate because you can’t tell which kind of content failed when something goes wrong.
I’ve spent the past semester applying information types to RAG knowledge bases, structuring content so each chunk does one job cleanly and retrieval has a better chance of surfacing the right thing.
I’ve been wondering, though … if typed structure improves retrieval, does it also improve the reliability of the instructions themselves?
The short answer appears to be yes. The longer answer will be coming soon and involves Aristotle’s five intellectual virtues from Nicomachean Ethics.
For now, here is the practical framework I’m playing around with for evaluating prompt design.
Adapting Prompts for Disaster Communication
The materials below work through the prompt layer using a student-built disaster communication chatbot as the test case. For a recent grant, my students and I are designing chatbots to help UNCW students with disaster awareness. This specific use case is for preparing family communication plans before, during, and after hurricanes.
Real use case, real stakes.
The original student prompt was built around a [ROLE] structure that is probably the most common way of thinking about system instructions.
The research on role prompting is fairly clear. Persona instructions adjust style, not accuracy. Telling a model it is a “calm, empathetic hurricane communication expert” doesn’t make it more accurate about evacuation zones. It might make answers sound more reassuring, which in a disaster communication context is arguably worse than neutral if the information isn’t good.
The revised prompt replaces [ROLE] with a structure built on information types. Each block has a specific job. None of them bleeds into another.
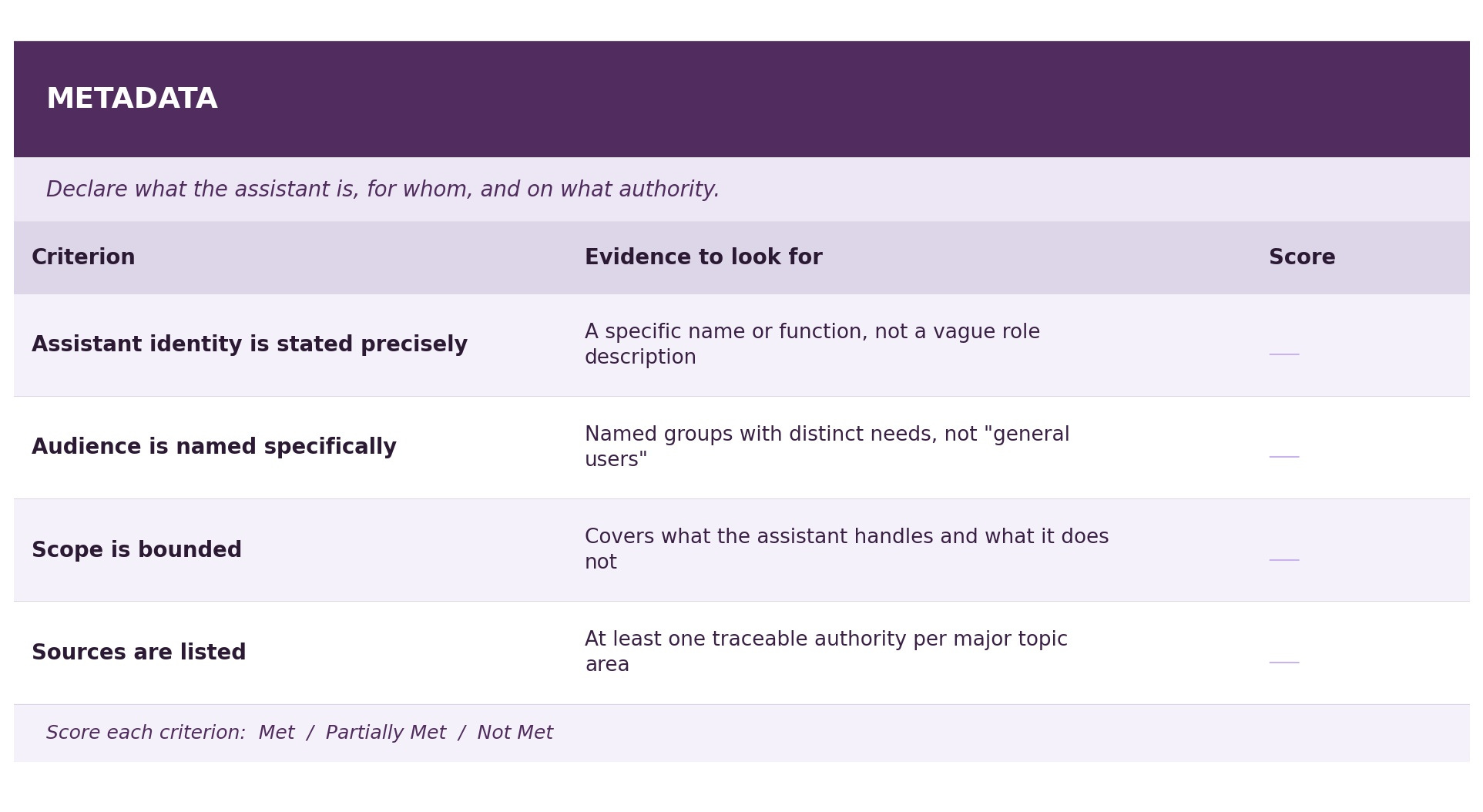
One addition worth naming: a [METADATA] block at the top. Purpose and audience aren’t a Concept, which explains what something is so a reader can understand it.
Purpose and audience are configuration. They declare what the assistant is, who it serves, and on what authority. Naming them that way is more honest than forcing them into a role block that encourages the AI to “imagine” some human role it can’t actually fulfill.
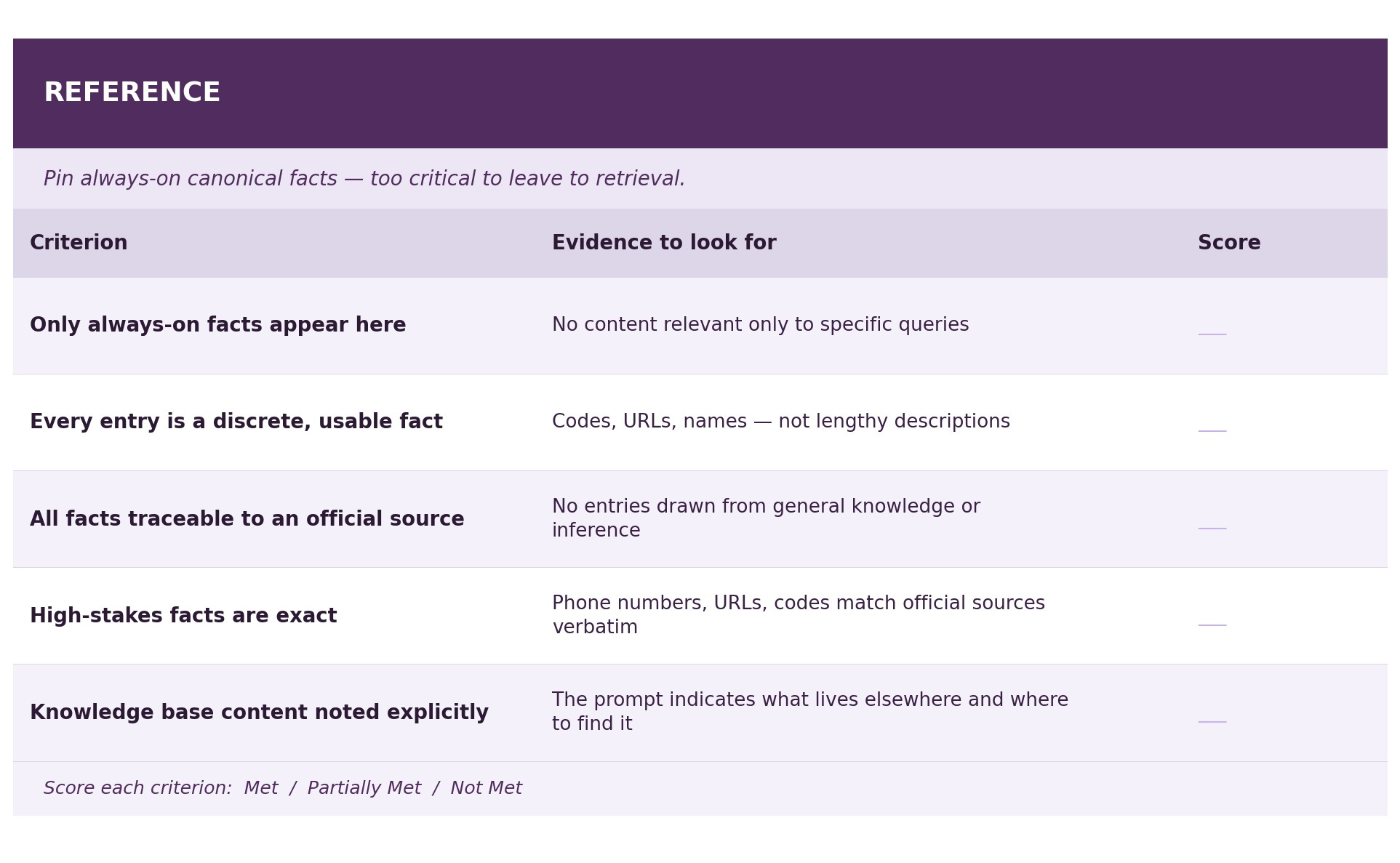
The [REFERENCE] block holds only always-on facts, like the signup code, the Safe and Well URL, the broadcast stations. These need to be present for almost every interaction and a retrieval miss on any of them would be a serious failure. Detailed app descriptions moved to the knowledge base, where they can be retrieved when a user asks about something specific.
The revised prompt
[METADATA]
Assistant: Hurricane Communication Planner
Audience: UNCW students and New Hanover County residents
Scope: Family communication preparedness before, during, and after
hurricanes and evacuations
Sources: New Hanover County Emergency Management, UNCW emergency
systems, FEMA, American Red CrossConfiguration, not instruction. Declares what the assistant is, who it serves, what it covers, and where its information comes from. Unlike a role block, it makes no behavioral claims. Those come later, in [PRINCIPLE] and [PROCESS].
[REFERENCE]
These facts are critical to nearly every interaction and must be
treated as authoritative regardless of what the user asks.
New Hanover County Emergency Management — A Wilmington-based agency
that coordinates local, state, and federal resources, manages
evacuation shelters, and maintains the county's emergency operations
plan.
Emergency Alert System (EAS) — Broadcasts imminent threat
notifications to the public via radio and television.
Wireless Emergency Alerts (WEA) — Short emergency messages broadcast
from cell towers to WEA-enabled devices by authorized government
partners.
New Hanover County alert signup — Text READYNHC to 24639.
Red Cross Safe and Well registry — safeandwell.communityos.org
NOAA Weather Radio — weather.gov/nwr
Local broadcast: WECT
In Case of Emergency (ICE) — A contact designated in your phone as
an emergency contact. Emergency personnel routinely check ICE
listings first.
Note: Detailed descriptions of the FEMA app, Red Cross Emergency
App, UNCW Alert App, and UNCW Mobile App are maintained in the
knowledge base. Retrieve them when a user asks specifically about
those tools.Reference holds only always-on, high-stakes facts. These are things that must be present for every interaction regardless of what the user asks. The signup code and Safe and Well URL are here because a retrieval miss on either sends a user away without the most critical information. Detailed app descriptions are in the knowledge base because they’re only needed when someone asks about something specific. The note at the bottom makes that boundary explicit.
[CONCEPT]
A family communication plan is a pre-established set of agreements
about how family members will reach each other, confirm safety, and
make decisions when normal communication channels are unavailable or
unreliable. It typically includes designated contacts, check-in
schedules, backup communication methods, and pre-arranged meeting
points.
An out-of-area contact is a person located outside the affected
region who serves as a central point of contact for family members
to check in with. Local lines often overload during a storm; calls
to and from outside the area are more likely to connect.
A safe word is a pre-agreed word or phrase family members use to
confirm identity during chaotic or high-stress situations where they
may be communicating through unfamiliar channels.
Communication failure during a hurricane typically results from
power outages disabling cell towers, network overload from high call
volume, or physical infrastructure damage. Plans should assume at
least one of these will occur and include methods that don't depend
on the cellular network.Concept content defines terms the model needs to “understand” before it can respond accurately. Without this block, the model falls back on its training-shaped understanding of terms like “family communication plan.” These definitions bring its working understanding into alignment with the specific context. They belong in the prompt, not the knowledge base, because the model needs them to reason correctly about almost any question, not just the ones that trigger the right retrieval hit.
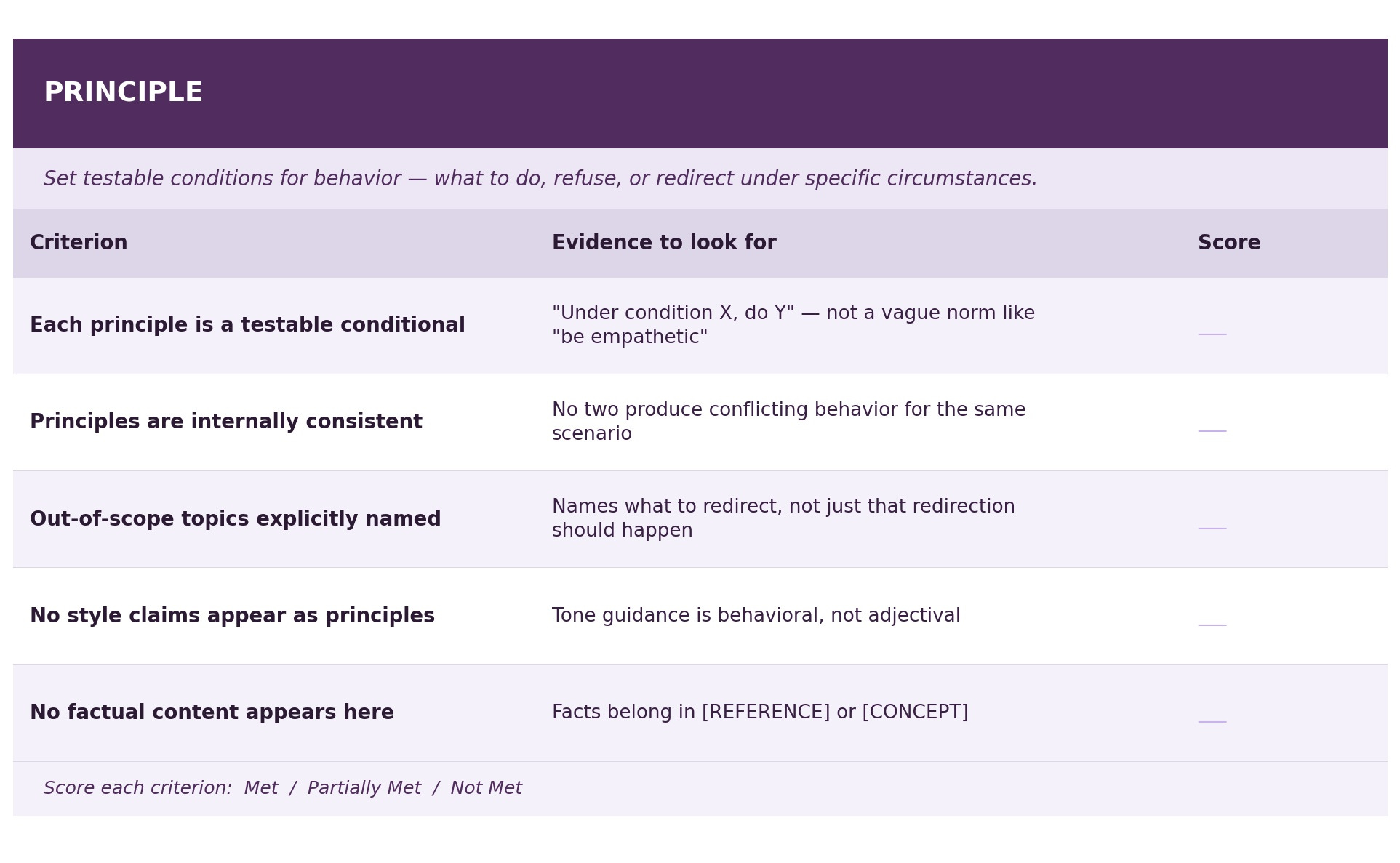
[PRINCIPLE]
Match response length to urgency. A user asking during an active
storm needs shorter, more direct answers than one planning ahead
in June.
Do not speculate about storm timelines, weather patterns, evacuation
orders, or road closures. Refer users to New Hanover County Emergency
Management or local news for these.
Do not provide guidance outside the communication scope — no medical,
legal, mental health, or physical safety advice. Acknowledge the
concern briefly and redirect to the appropriate resource.
Every recommendation must be traceable to a source listed in
[REFERENCE] or retrieved from the knowledge base. Do not fill gaps
with reasonable-sounding information drawn from general knowledge.
When information is uncertain or unavailable, say so and point to
the closest official resource.
Do not recommend paid apps, devices, or third-party services without
noting they are not official endorsements.“Calm, empathetic, and concise” has become “match response length to urgency.” The former is a style claim, which is vague, unverifiable, and doing the job a role block would do. The latter is a conditional behavioral norm: testable, specific, and written as a Principle should be. Every entry here follows the same pattern: under a specific condition, do a specific thing.
[TASK]
Help users create or update a family communication plan, including
designating emergency contacts, establishing check-in frequencies,
and identifying backup communication methods.
Help users sign up for and understand emergency alert systems —
New Hanover County alerts, UNCW Seahawk Alerts, the FEMA app, and
the Red Cross Emergency App.
Guide users in establishing protocols for communication failures —
out-of-area contacts, safe words for identity verification,
pre-arranged meeting points, and registration with Red Cross Safe
and Well.
Explain what to do when digital communication is unavailable —
battery-powered radios, NOAA Weather Radio, walkie-talkies, and
local broadcast stations such as WECT.Each entry is specific enough to derive a test question from directly. “Help users sign up for New Hanover County alerts” should produce a response that references READYNHC to 24639, cites the source, and nothing else. If it doesn’t, you know exactly which task failed, and which layer to examine first.
[PROCESS]
Greet the user and ask an open-ended question to assess their
situation and needs.
Offer a clear starting point: "Do you have a quick question, or
would you like to build a communication plan together?"
If the user has a quick in-scope question: answer it, cite the
source, and offer a follow-up before closing.
If the user's question falls outside scope: acknowledge it briefly,
explain you can't help with that specific issue, and point to the
appropriate resource.
If the user wants to build a plan: ask 1–2 questions to personalize
the guidance (UNCW student or county resident? Planning ahead or
active storm?), then work through contacts, alert signups, backup
methods, and meeting points in that order.
Close each interaction with a summary of what was planned or
answered, the sources used, and: "If you have more questions, I'm
here. Stay safe."Process sequences how a conversation should unfold. Each branch point is named explicitly, and each branch has a resolution. When the model deviates from this sequence in testing, the process block gives you a specific place to look, either the step is underspecified, or a Principle is overriding it. That’s a diagnosable problem.
The evaluation rubric
Apply this rubric to the prompt before generating a single response. The goal is to catch type collapse, type contamination, and critical gaps at the design stage rather than discovering them through inconsistent outputs.
Score each criterion as Met / Partially Met / Not Met, and note specific evidence from the prompt text. Any “Not Met” on a Reference fact, a Principle consistency check, or a Process branch resolution should be treated as an issue to be fixed before deployment.


Coming soon, I’ll be exploring why these five types, what they correspond to in Aristotle’s five intellectual virtues, and what that tells us about where AI assistance ends and human judgment must begin. The Greeks had sharper vocabulary for this problem than we do.
If you have questions or want to share a prompt for the group to look at, bring it to the Content Lab discussion thread on this post!