


This episode has been a long time coming, as I finish up a busy semester.
One of the things consuming most of my attention lately is a research grant I’m running with a colleague in computer engineering.
Students are building structured chatbots for disaster communication, then assessing and documenting how those systems actually perform.
More on that soon.
But a question keeps surfacing in that work: how do we actually evaluate an AI system? What counts as evidence? And how do we measure it in ways that are meaningful, not just convenient?
I’m Lance Cummings. And welcome to my intermittent (or aspirationally biweekly) podcast that explores deep research on AI and writing.
That question about evidence sent me back to a paper I probably should have read years ago.
What is evidence?
I’m actually not sure if “evidence-based” gets attached to AI evaluation much, but the assumption is certainly their in the workplace and research lab.
Use data. Test your prompts. Measure outputs. That seems to be evidence based.
But what does evidence-based actually require?
The term comes from a 1996 editorial by David Sackett and colleagues that launched the evidence-based medicine movement.
He defined evidence-based, as the conscientious, explicit, and judicious use of current best evidence in making decisions about the care of individual patients.
Its pretty easy to stop there. Run the study, then follow the data. But Sackett immediately complicated it.
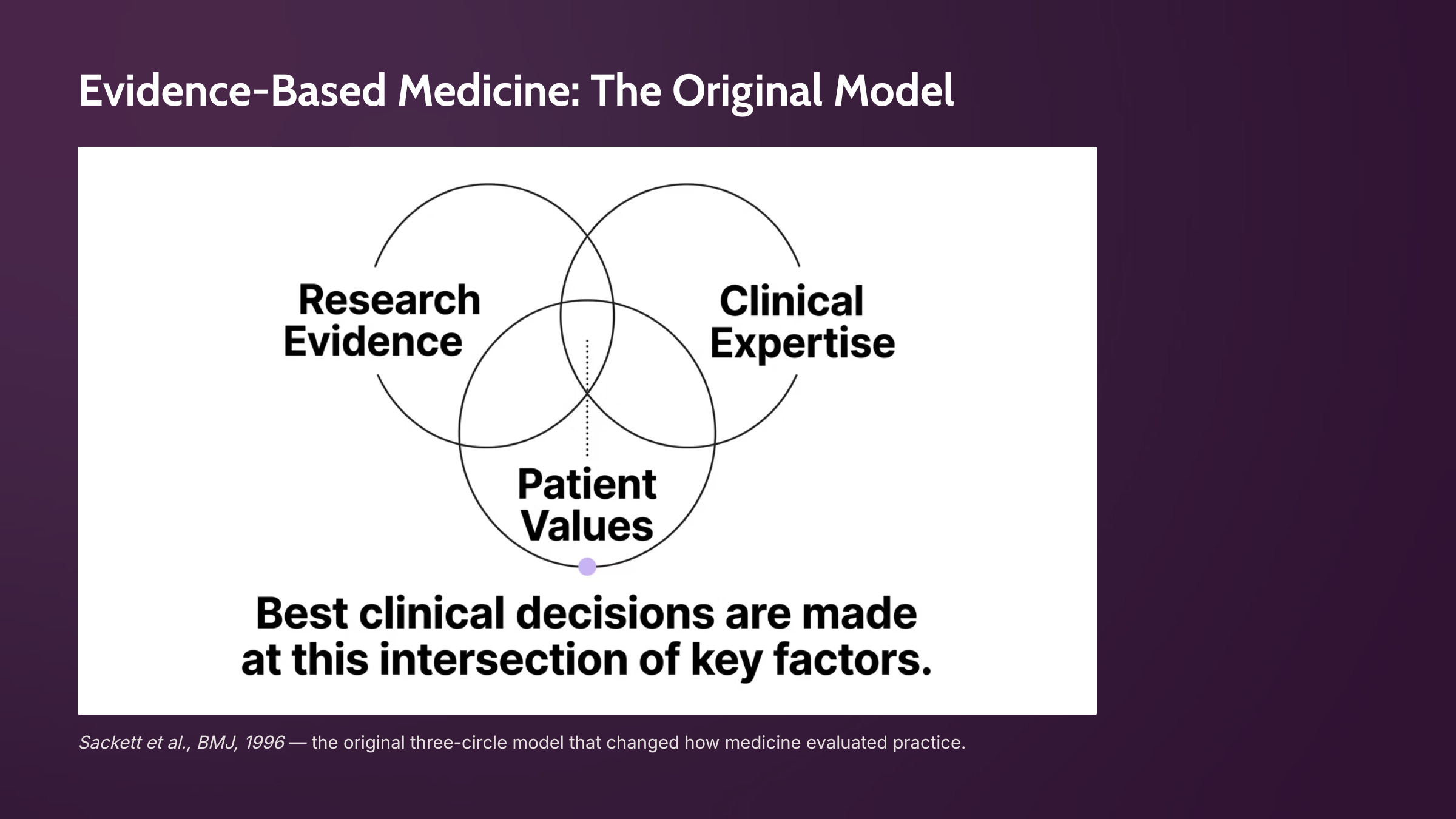
He drew a model with three overlapping circles and said all three were required: research evidence, professional expertise, and patient values.
“Without clinical expertise, practice risks becoming tyrannised by evidence, for even excellent external evidence may be inapplicable to or inappropriate for an individual patient.”
For those of us doing AI work, the substitution is straightforward.
Replace “clinical expertise” with communication expertise. Replace “individual patient” with your specific audience and their context.
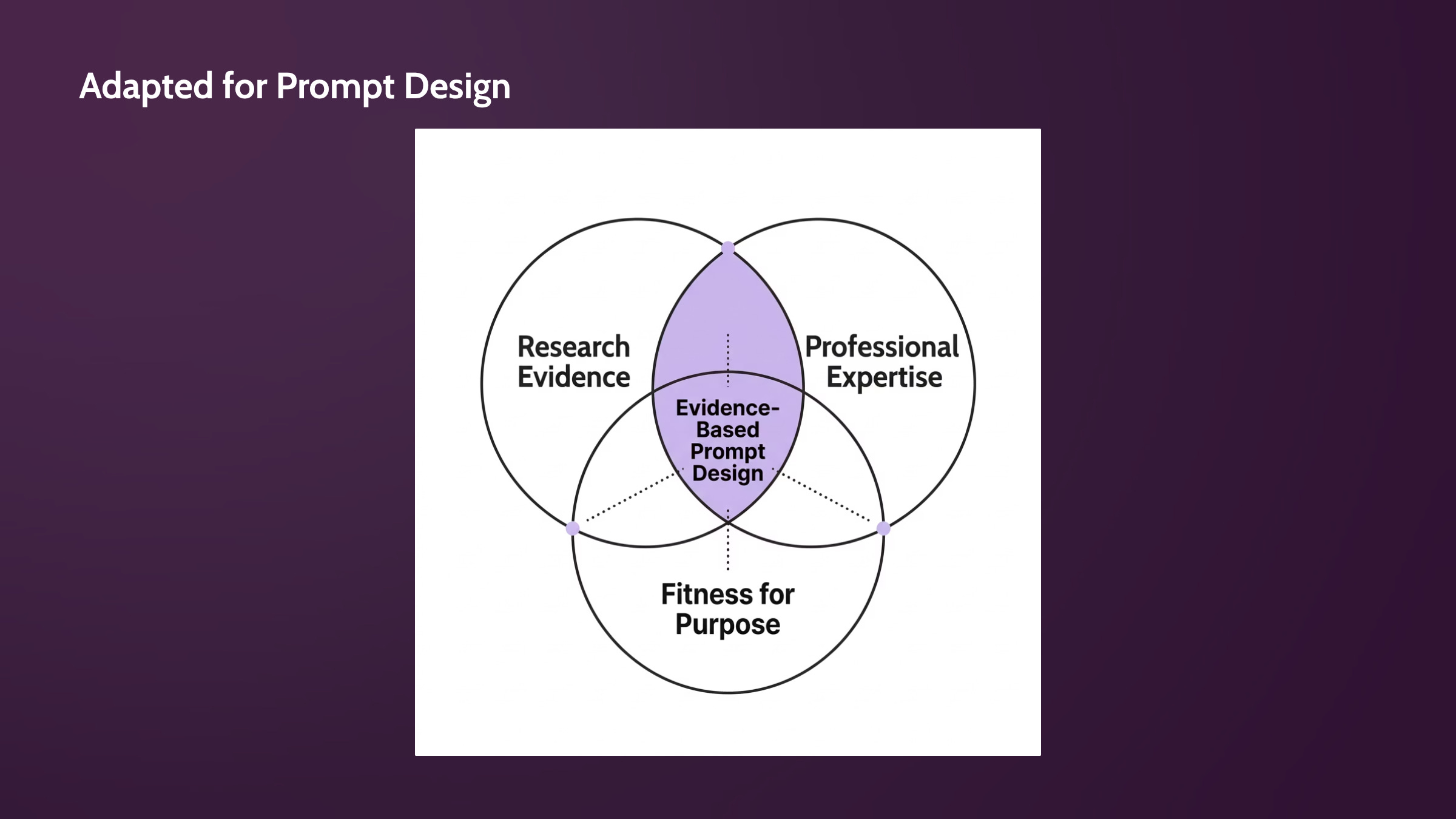
That gives us our own definition: the conscientious, explicit, and judicious use of current best evidence, integrated with professional expertise about genre and communication context, evaluated against whether the output actually serves the person who needs it.
Any comprehensive analysis of an AI content system needs more than just numbers … it needs rhetorical analysis.
Numbers are great, but they are only half the picture.
The evaluator isn’t neutral
But even the numbers have problems, and is one reason rhetoric is crucial for evaluating AI writing systems.
Many people assume the research evidence circle is at least the most objective, but that is very difficult to achieve with AI and content.
Panickssery and colleagues challenge that directly. They showed that LLMs systematically favor their own outputs when used as evaluators. Fine-tune a model to better recognize its own text, and the self-preference bias scales proportionally.
Subsequent work has extended this by showing that bias runs across model families and found that evaluator LLMs missed intentionally degraded outputs more than half the time (Spiliopoulou et al. 2025; Doddapaneni et al. 2024) .
Human evaluation has its own distortions. Hosking and colleagues found that human raters consistently score assertive but incorrect outputs higher than accurate but hedged outputs. Confident and wrong beats careful and right.
For our disaster communication project, this means we can’t treat any single evaluation method as definitive. Which brought me to the rubric question, and to some research from education that I didn’t expect to find relevant.
A cautionary tale from education
Back in 2015, Terry Wrigley traced what happens when education tries to adopt evidence-based medicine’s framework.
Too often evidence-based models are imposed on teachers (or practitioners) from the top down, disregarding practitioner points of view. Here’s what the research says, now do it.
Education is an open, recursive system … not a closed laboratory. What works in one classroom may not transfer, and assuming it should distorts practice.
AI prompting is the same kind of system. A model’s response changes the context for the next interaction. Effects are interpretation-dependent.
The Wharton Generative AI Lab’s finding that prompt engineering effects are “complicated and contingent” … that is rhetorical, what Aristotle calls phronesis, or practical wisdom, the kind of judgment that can't be reduced to rules or replicated from a checklist.
Phronesis is what you develop by doing, by failing, by adjusting. This is the kind of skill and knowledge that makes evidence work in our complex situations.
We need stop treating AI systems as an optimization problem and started framing it as a rhetorical one that requires practical wisdom.
Most of us already know automated evaluation is imperfect — and keep using it as if it weren’t, because the alternative takes time and doesn’t produce a clean number.
I’m not saying abandon it, but be precise about what it can and can’t tell you. An LLM-as-judge gives signal on fluency, consistency, surface coherence. It can’t tell you whether the output serves the person who needs it. Those are different questions, and the first doesn’t substitute for the second.
Takeaways for content professionals and technical writers
When evaluating an AI output, ask the question no metric answers for you: does this serve the actual person who needs it, in this context, for this purpose?
Building a rubric that does that requires moving beyond “is this accurate?” toward questions about usability and audience fit.
In our disaster communication project, for instance, one rubric dimension asks: could a coastal resident with limited English act on this message during an active evacuation?
That kind of question builds in audience, context, and purpose — Sackett’s three circles translated into evaluation criteria.
I’ll be sharing the full rubric we’re developing soon for paid subscribers.
Your own systematic, rubric-driven testing is legitimate evidence, not some kind a fallback, and an important part of showing employers your value.
The key is knowing how to communicated it
➡️ That’s the core skill my Writing with Machines course is designed to build. It’s structured around developing an AI portfolio with real documentation. I’m giving paid subscribers free access till the end of June.
Our disaster communication project is going to push all of this into territory I haven’t fully mapped yet.
How do you evaluate a chatbot that might need to reach someone in crisis, on a bad connection, possibly in their second language?
Benchmark scores won’t settle that. But Sackett’s three circles might be the right place to start.
More on that soon.
I’m Lance Cummings. Until next time — use all three circles: research, practitioner wisdom, and user values.
References
Doddapaneni, S., Khan, M. S. U. R., Verma, S., & Khapra, M. M. (2024). Finding blind spots in evaluator LLMs with interpretable checklists. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 16279–16309). Association for Computational Linguistics. https://aclanthology.org/2024.emnlp-main.911/
Hosking, T., Blunsom, P., & Bartolo, M. (2024). Human feedback is not gold standard. The Twelfth International Conference on Learning Representations. https://arxiv.org/abs/2309.16349
Khullar, D., Hopkins, J., Wang, R., & Roger, F. (2026). Self-attribution bias: When AI monitors go easy on themselves. arXiv. https://arxiv.org/abs/2603.04582
Panickssery, A., Bowman, S. R., & Feng, S. (2024). LLM evaluators recognize and favor their own generations. Advances in Neural Information Processing Systems, 37. https://arxiv.org/abs/2404.13076
Sackett, D. L., Rosenberg, W. M. C., Gray, J. A. M., Haynes, R. B., & Richardson, W. S. (1996). Evidence based medicine: What it is and what it isn’t. BMJ, 312(7023), 71–72. https://pmc.ncbi.nlm.nih.gov/articles/PMC2349778/
Spiliopoulou, E., Fogliato, R., Burnsky, H., Soliman, T., Ma, J., Horwood, G., & Ballesteros, M. (2025). Play favorites: A statistical method to measure self-bias in LLM-as-a-judge. arXiv. https://arxiv.org/abs/2508.06709
Wrigley, T. (2015). Evidence-based teaching: Rhetoric and reality. Improving Schools, 18(3), 277–287. https://eric.ed.gov/?id=EJ1079308

